当前位置: 首页 > 网络学院 > XML相关教程 > XML DOM > DOM 节点导航
 XML DOM 中的 DOM 节点导航
XML DOM 中的 DOM 节点导航
Navigating DOM Nodes
DOM 节点导航
We can navigate between nodes by using their relationship to each other:
我们可以通过利用节点之间的彼此关系在节点间进行导航:
- parentNode
父类节点 - childNodes
子类节点 - firstChild
第一个子节点 - lastChild
最后一个子节点 - nextSibling
下一个同属类节点 - previousSibling
上一个同属类节点
Look at the following XML file: books.xml.
请看这份XML文件:books.xml。
The following image illustrates a part of the node tree and the relationship between the nodes in the XML file above:
下面这幅图展示了节点树的一个部分,同时指明了上述XML文件中节点之间的关系:
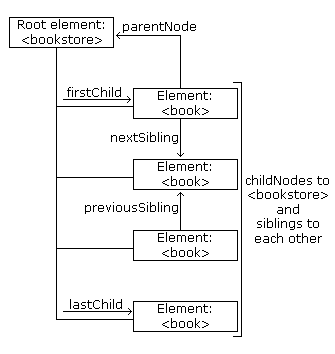
Note: Internet Explorer will skip white-space text nodes that are generated between nodes (e.g. new-line characters), while Mozilla will not. So, in the examples below, we have a function that checks the node type of a node when using the firstChild, lastChild, nextSibling and previousSibling properties.
注意:Internet Explorer会忽略节点之间产生的空白文本节点(例如换行字符),而Mozilla不会这样。因此在下面的例子中,当我们使用firstChild、 lastChild、nextSibling以及 previousSibling属性时,会使用一个函数来检测节点的类型。
Get the First Child of a Node
获取节点的第一个子元素
The following code fragment gets the first child node of <bookstore>:
下述代码片段可以获得<bookstore>的第一个子节点:
//check if the first node is an element node xmlDoc=load("books.xml"); var y=get_firstchild(xmlDoc.documentElement); document.write(y.nodeName); |
The output of the code above will be:
上述代码将输出下述结果:
book |
The function in the example above checks the node type of the first child node.
上述案例检验了第一个子节点的节点类型。
Element nodes has a nodeType of 1, so if the first child node is not an element node, it moves to the next node, and checks if this node is an element node. This continues until the first child node (which must be an element node) is found. This way, the result will be correct in both Internet Explorer and Mozilla.
元素节点的节点类型是1,因此如果第一个子节点不是元素节点,它就会移至下一节点并检查此节点是否是元素节点。这个过程会持续到第一个元素被找到为止。通过这个办法,我们在Internet Explorer和Mozilla中都会得到正确的结果。
Get the Previous Sibling of a Node
获取节点的上一个同属节点
The following code fragment gets the previous sibling node of the first <author> element:
下述代码片断将获取第一个<author>元素的上一个同属节点:
//check if the previous sibling node is an element node xmlDoc=load("books.xml"); var x=xmlDoc.getElementsByTagName("author")[0]; var y=get_previoussibling(x); |
The output of the code above will be:
上述代码将输出下面的结果:
title |
The function in the example above checks the node type of the previous sibling node.
上述案例中的函数将检验上一个同属节点的节点类型。
If the previous sibling node is not an element node, it moves to the "next" previous sibling, and checks if that node is an element node. This continues until the previous sibling node (which must be an element node) is found. This way, the result will be correct in both Internet Explorer and Mozilla.
如果上一个同属节点不是一个元素节点,它就会移至下一个前面的同属节点,并检查此节点是否是元素节点。这个过程会持续到上一个同属的元素节点被找到为止。通过这个方法,我们就可以在Internet Explorer和Mozilla中得到正确的结果。
 DOM 文档执行
无
DOM 文档执行
无 
 评论 (0) All
评论 (0) All
